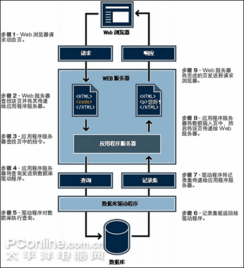

在当今的数字化世界中,数据已经成为了一种宝贵的资源。数据的收集、存储和使用也带来了隐私泄露的风险。特别是当数据与用户的敏感信息和个体身份相关联时,这种风险更为显著。因此,为了保护用户的隐私,我们需要开发有效的隐私保护模型。其中,K-匿名模型是一种被广泛接受的隐私保护方法。

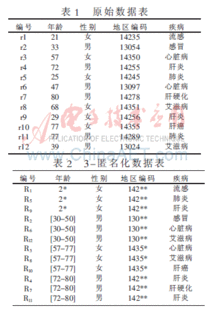
K-匿名模型是一种数据发布技术,旨在保护个体隐私的同时,满足数据使用者的需求。它的基本思想是通过概括和隐匿技术,发布精度较低的数据,使得每条记录至少与数据表中其他k-1 条记录具有完全相同的准标识符属性值。这样,即使攻击者拥有关于个体的丰富个人信息和大量全局信息,也无法准确地识别出目标个体。

K-匿名模型已被广泛应用于各种领域,如医疗、金融和社交网络等。在医疗领域,为了保护患者的隐私,K-匿名模型常被用于发布医疗数据。在金融领域,K-匿名模型可用于发布财务报表,以避免泄露公司的敏感信息。在社交网络中,K-匿名模型可以隐藏用户的真实身份,保护其隐私。

尽管K-匿名模型在保护隐私方面表现出色,但它也面临着一些挑战。例如,如何平衡隐私保护和数据精度是一大挑战。过于粗糙的数据可能会影响数据使用者的决策准确性。K-匿名模型并不能完全防止链接攻击,攻击者仍有可能通过其他渠道获取敏感信息。因此,未来的研究需要进一步探索如何提高K-匿名模型的隐私保护能力。
K-匿名模型是一种有效的隐私保护方法,它通过发布精度较低的数据来防止个体隐私的泄露。尽管存在一些挑战,如平衡隐私保护和数据精度以及防止链接攻击等,但K-匿名模型在医疗、金融和社交网络等领域的应用证明了其价值和潜力。随着技术的不断发展,我们期待K-匿名模型在未来能够更好地保护个人隐私,同时满足各种数据使用需求。
 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条
头条
头条 头条
头条