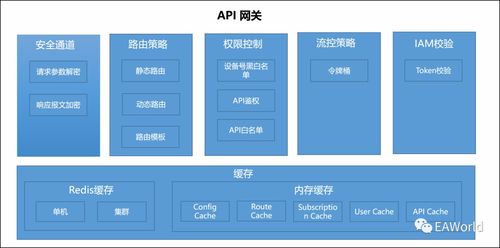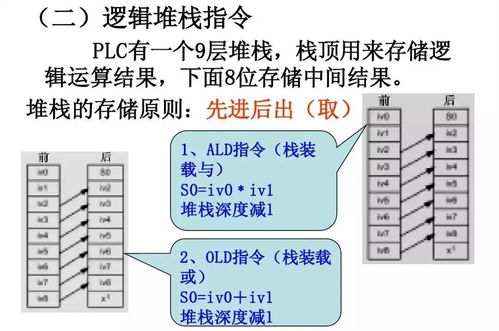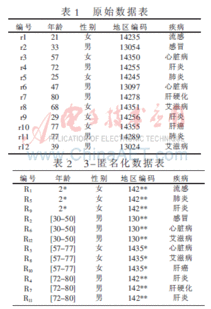
随着信息时代的快速发展,大数据技术已经在各个领域得到广泛应用。数据隐私保护问题也日益凸显。为了保护个人隐私,k匿名隐私保护模型应运而生。
k匿名隐私保护模型是一种在数据发布和分析过程中保护隐私的方法。它通过在数据集中找到k个最相似的记录,并将其作为隐私保护的“锚点”,以避免单一记录被准确地识别或关联。这样,即使攻击者获取了数据集,也无法准确地确定某个特定个体的信息。
k匿名隐私保护模型的优势在于其灵活性和适用性。它可以应用于各种数据集和场景,包括社交网络、医疗、金融等。k匿名隐私保护模型还可以与其他隐私保护技术结合使用,如差分隐私、同态加密等,以提供更高级别的隐私保护。
k匿名隐私保护模型也存在一些挑战和限制。确定k个最相似的记录需要消耗大量的计算资源和时间。对于某些数据集,可能很难找到满足要求的k个最相似的记录。攻击者可能会采用一些技术手段来绕过k匿名隐私保护模型,从而获取到敏感信息。
为了克服这些挑战和限制,研究人员提出了许多改进和优化方法。例如,采用更高效的相似度计算方法、利用机器学习技术自动确定k值、引入差分隐私技术来提高隐私保护强度等。这些方法在提高k匿名隐私保护模型的性能和安全性方面取得了显著进展。
k匿名隐私保护模型是一种重要的数据隐私保护方法。它通过找到k个最相似的记录作为“锚点”,以避免单一记录被准确地识别或关联。该模型仍存在一些挑战和限制,需要进一步的研究和改进。随着技术的不断发展和进步,我们有信心克服这些挑战,为数据隐私保护提供更强大、更有效的解决方案。
 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条