随着大数据时代的来临,数据处理已经成为企业和组织不可或缺的一部分。为了应对海量数据带来的挑战,许多数据处理平台应运而生。本文将介绍几种常见的大数据处理平台,帮助读者了解它们的特点和应用场景。
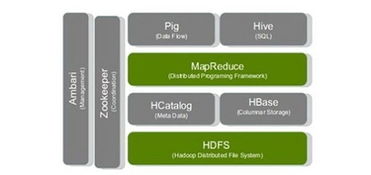
Hadoop是Apache开源社区开发的一种分布式计算框架,用于处理大规模数据集。Hadoop通过将数据分片并分布到多个节点进行处理,可以处理传统数据库无法处理的数据规模。Hadoop的核心组件包括分布式文件系统HDFS、MapReduce计算框架和YAR资源管理器。Hadoop适合处理非结构化数据和流数据,广泛应用于数据仓库、数据挖掘和机器学习等领域。

Apache Spark是一个开源的大数据处理框架,它提供了高性能、可扩展和易用的数据计算能力。Spark通过将数据分发到集群中的节点进行分布式计算,具有更快的处理速度和更灵活的处理方式。Spark适合处理大规模的迭代算法和实时数据处理。它可以与Hadoop集成,共同实现混合负载处理,适用于流计算、批处理和图计算等多种场景。

Apache Flik是一个流处理和批处理的开源框架,它提供了高性能、低延迟的数据处理能力。Flik基于流式处理模型,支持实时数据流和批数据的统一处理。Flik适用于实时数据分析、在线机器学习、数据管道和ETL等场景。它还提供了多种API和SQL接口,方便用户进行数据处理和分析。

Apache Sorm是一个分布式实时计算系统,用于处理高速数据流。Sorm通过将数据分发到集群中的节点进行实时计算,具有高可靠性和可扩展性。Sorm适用于实时数据分析、实时机器学习、实时推荐系统和实时搜索引擎等场景。它还提供了简单的API和编程模型,方便用户进行开发和应用。

Apache Kafka是一个分布式流平台,用于构建实时数据管道和流应用。Kafka通过将数据分发到集群中的节点进行存储和传输,可以高效地处理大规模的流数据。Kafka适用于日志收集、事件驱动微服务和实时数据分析等场景。它还提供了高可靠性和可扩展性,以及多种API和连接器,方便用户进行数据处理和集成。

Apache Beam是一个开源的流处理和批处理的编程模型和执行引擎。Beam提供了统一的编程模型,支持多种数据处理引擎,包括Apache Flik、Apache Spark和Google Cloud Daaflow等。Beam适用于多种数据处理场景,如实时数据分析、批处理和ETL等。它还提供了多种API和工具,方便用户进行数据处理和分析。
常见的大数据处理平台包括Hadoop、Spark、Flik、Sorm、Kafka和Beam等。它们各自具有不同的特点和适用场景,可以帮助企业高效地处理大规模的数据集。了解这些平台的原理和使用方式对于企业实现数据驱动的业务增长至关重要。在实际应用中,根据具体的需求和场景选择合适的大数据处理平台,能够充分发挥数据的价值并为企业带来更大的收益。
 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条